
Introduction:
My previous post looked into most linked domains, in popular subreddits across the world. In that exploratary data analysis, I took a cluster of subreddits and did a comparative analysis of how (news-) domains linked, vary in their proportions within a cluster of subreddits. To a novice redditor though, it isn’t always clear which subreddits are alike, say, in terms of what they are about (for example, US Politics Wiki-rules), or, in terms of spatial proximity of subreddits, as extrapolated from redditors’ activity.
Reddit does provide a search box in its user interface, where you can enter a keyword, and get a list of recommendations, along with a serendipty recommendation.
While attempting at my version of it, I came across these blogs on Finding Similar Music using Matrix Factorization by Ben Frederickson and Recommending GitHub Repositories with Google BigQuery and the implicit library by Juarez Bochi and both of them turned out to be very helpful in structuring the approach.
Content-based and Collaborative-filtering approaches:
To start with, recommender systems are broadly classified into two types: content-based and collaborative-filtering. There are other approaches also: e.g. demographics based, social-recommendation based, or hybrid approach which combines any or all of the above approaches.
In Content-based filtering, we look at attributes or meta-data of the items, and try to build an user-profile by combining the item-profiles from user’s history. Then we build a utility-function (or) a classifier for the user, to predict whether the user will like or dislike a new-item, by using a distance-measure, between user-profile and the item-profile of new-item. While this approach doesn’t need other users’ data, it has some major disadvantages such as: requiring items to be described in standard attributes (which means finer aesthetics of item can’t be captured), not making use of similar-users’ preferences, and lack of serendipity in recommendation.
Collaborative filtering looks at user’s past behavior as well as behavior exhibited by similar users. CF model can be built using explicit feedback (e.g. user’s explicit rating) or implicit feedback like clicks, page-visits, video-plays etc. Here in reddit, there is no such explicit rating mechanism whilethere is plenty of implicit-feedback (posts, comments activity). It may seem counter-intuitive, but often, implicit feedback is preferred as it is less noisy and easy to gather, than explicit feedback which is often scarce and gets noisy due to distortion in rating from one’s aspiration towards an item.
In this post, I use a random-sample of reddit posts data and make use of matrix-factorization in implicit library (it implements the paper Collaborative Filtering for Implicit Feedback Datasets) to come up with the recommendations.
Data Preparation:
First let’s look at average number of subreddits, to which an author generally posts to:
query = """
WITH posts AS (
SELECT author, COUNT( DISTINCT subreddit) as n_subreddits
FROM `fh-bigquery.reddit_posts.2017_09`
GROUP BY author
)
SELECT
n_subreddits, COUNT( DISTINCT author) AS n_authors
FROM posts
GROUP BY n_subreddits
ORDER BY n_subreddits
"""
data = pd.io.gbq.read_gbq(query, dialect="standard", project_id=project_id)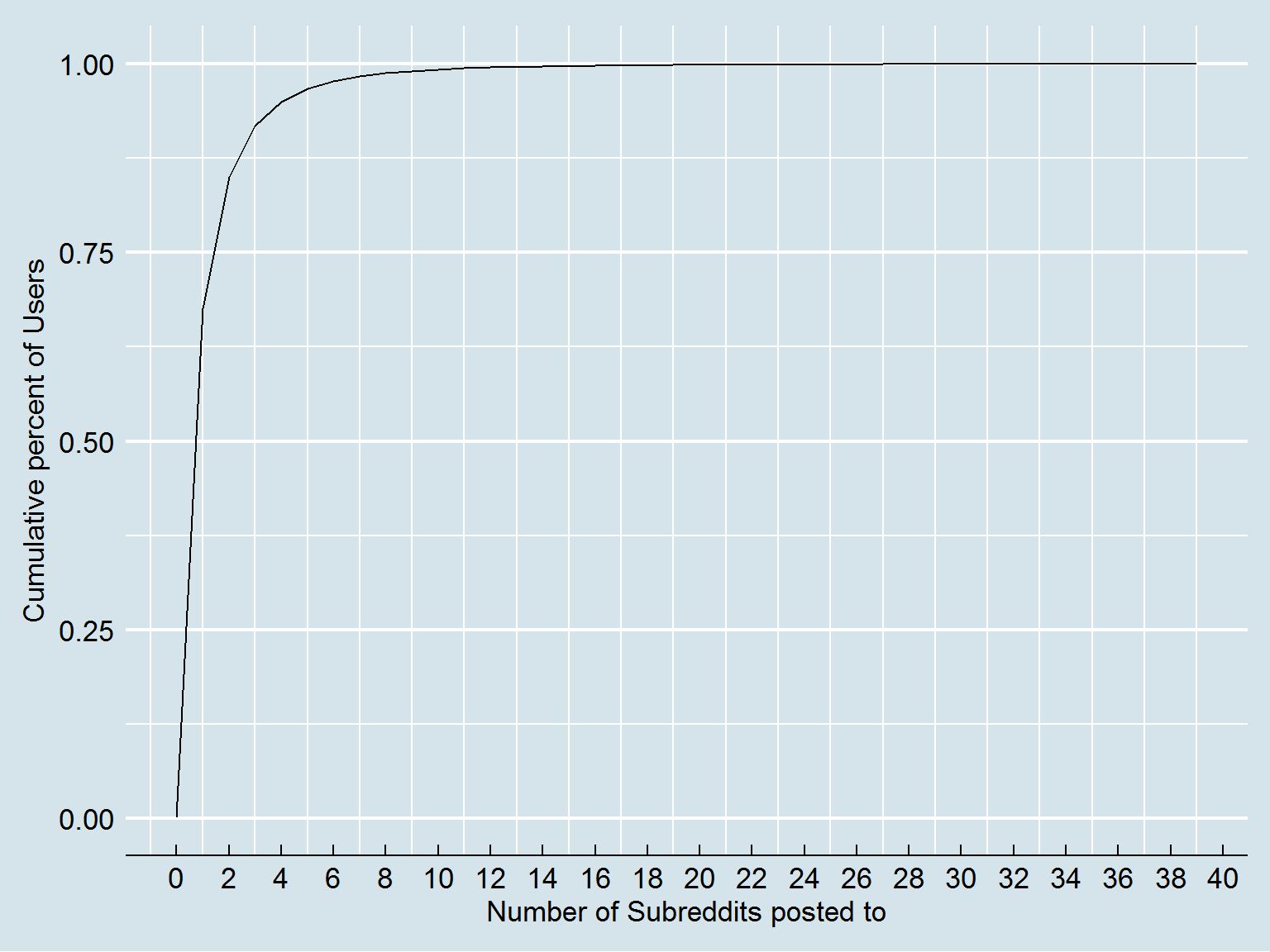
While a majority of users post to less than 10 subreddits in a month, there are authors who have posted to 100+ subreddits (this includes reddit’s automatic news bots too); let’s restrict our analysis to typical users, say, authors who posted to <= 15 subreddits: they constitute almost all ( 99.7% ) of active users (in terms of ‘posts’ activity).
In further analysis, I consider authors who posted to 2 to 15 subreddits. For simplicity, let’s restrict to top 2000 subreddits (as ranked by number of unique active authors) and pick a random sample of 100K authors. Final dataset thus comprises of all those authors (from 100K authors sample) who made non-zero posts to top 2000 subreddits.
query = """
WITH posts AS (
SELECT author, subreddit, COUNT(*) as n_posts
FROM `fh-bigquery.reddit_posts.2017_09`
WHERE score > 0 AND over_18 IS FALSE
GROUP BY author, subreddit
HAVING n_posts > 1
),
subreddits_posts AS (
SELECT subreddit, COUNT(DISTINCT author) as c
FROM posts
GROUP BY subreddit
ORDER BY c DESC
LIMIT 2000
),
authors_posts AS (
SELECT author, COUNT(DISTINCT subreddit) as c
FROM posts
WHERE subreddit IN (SELECT subreddit FROM subreddits_posts)
GROUP BY author
HAVING c > 1 AND c <= 15
LIMIT 100000
)
SELECT
author, subreddit, n_posts
FROM posts
WHERE subreddit IN (SELECT subreddit FROM subreddits_posts)
AND author IN (SELECT author FROM authors_posts)
ORDER BY n_posts DESC
"""
data_posts = pd.io.gbq.read_gbq(query, dialect="standard", project_id=project_id)data_posts.head(5) author subreddit n_posts
0 boundaryrope Cricket 2
1 snowfox251 Rainbow6 2
2 Tele_Prompter de 2
3 martinritasingh business 2
4 DarkyLights Undertale 2A quick peek into summary of the data shows there are some users who have made 2000+ posts to a subreddit.
# summary of data-set
data_posts.describe() n_posts
count 150809.000000
mean 5.058889
std 16.927081
min 2.000000
25% 2.000000
50% 3.000000
75% 4.000000
max 2867.000000To work around this, I limit dataset to only entries of <=160 posts which is ~99.9th percentile in the data-sample. Let’s look at number of unique subreddits and authors in new filtered-dataset.
data_posts = data_posts[data_posts.n_posts <= np.percentile(data_posts.n_posts, 99.9) ]
# Number of unique subreddits, authors in dataset
data_posts.subreddit.nunique(), data_posts.author.nunique()(1994, 59182)Though there are as many unqiue subreddits and authors, the matrix overall is very sparse with few filled entries, thanks to the extreme diversity in the way users participate in reddit communities. In this case, we have only 1.03% of matrix-cells filled with a value.
# Sparsity of the matrix
sparsity = 100 * (1 - data_posts.shape[0]/(data_posts.subreddit.nunique() * data_posts.author.nunique()))
print('Sparsity of matrix: %.2f percent' %sparsity)Sparsity of matrix: 99.87 percentMatrix Factorization helps us here in finding general patterns, by mapping subreddits and authors to n latent factors which try to capture maximum possible variability in original sparse-matrix.
Model Fitting:
data_posts = data_posts[data_posts.n_posts <= 160]
# map each subreddit and author to a unique categorical code
data_posts['author'] = data_posts['author'].astype("category")
data_posts['subreddit'] = data_posts['subreddit'].astype("category")
# create a sparse matrix of all the authors/subreddits
actives = coo_matrix((data_posts['n_posts'].astype(np.float64),
(data_posts['subreddit'].cat.codes.copy(),
data_posts['author'].cat.codes.copy())))# initialize and train model
model = AlternatingLeastSquares(factors=50,
regularization=0.01,
dtype=np.float64,
iterations=50)
# Map the n_posts variable in subreddit x author matrix to its BM25 equivalent
# BM25 is, roughly, a better version of TF-IDF metric
# http://www.benfrederickson.com/distance-metrics/
actives = bm25_weight(actives, K1=100, B=0.8)
# Pass matrix of BM25 values, to implicit algorithm
# Algorithm maps authors and subreddit into latent-dimensions of 50 factors
model.fit(actives)Here I have mapped n_posts into BM25 equivalent before passing the sparse-matrix for further matrix-factorization. TF-IDF approach, and other ways of measuring similarity between two entities, are explained in detail in this blog by the author of ‘implicit’ package.
# dictionaries to translate names to ids and vice-versa
subreddits = dict(enumerate(data_posts['subreddit'].cat.categories))
subreddits_ids = {r: i for i, r in subreddits.items()}Now that we have model ready, let’s see the similar subreddits.
Find similar subreddits:
/r/politics
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['politics'])][('politics', 1.0000000000000002),
('environment', 0.87256491185317131),
('worldnews', 0.86658125965518107),
('esist', 0.85225822425160058),
('inthenews', 0.84332178093083832),
('MarchAgainstTrump', 0.84067819666650712),
('democrats', 0.83176377147009295),
('offbeat', 0.81102110011663076),
('nottheonion', 0.8057358816950505),
('Bad_Cop_No_Donut', 0.80488184365418369)]/r/worldnews
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['worldnews'])][('worldnews', 1.0000000000000002),
('news', 0.87487712646659022),
('politics', 0.86658125965518107),
('UpliftingNews', 0.85072298844006966),
('offbeat', 0.83173595719496218),
('inthenews', 0.81859113133471684),
('environment', 0.79155857305394062),
('TrueReddit', 0.77961627898785923),
('nottheonion', 0.75743456333522852),
('worldpolitics', 0.7365447319996693)]/r/europe
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['europe'])][('europe', 1.0000000000000002),
('unitedkingdom', 0.80390909997386562),
('syriancivilwar', 0.780741489260116),
('ukpolitics', 0.77025272815986912),
('de', 0.7574120150909972),
('LabourUK', 0.74397124973569562),
('Scotland', 0.72138801028850219),
('SyrianCirclejerkWar', 0.71167918704427369),
('Romania', 0.70603745470495449),
('Turkey', 0.7026006465476422)]/r/science
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['science'])][('science', 1.0000000000000004),
('EverythingScience', 0.93414776008424638),
('psychology', 0.89759141658483677),
('space', 0.89404927937862244),
('Futurology', 0.84796402066138654),
('news', 0.77473057040176496),
('Astronomy', 0.76680323773153269),
('Physics', 0.75211901150918992),
('energy', 0.73040888104728274),
('environment', 0.72954976604889632)]/r/movies
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['movies'])][('movies', 1.0),
('CastRecordings', 0.97764694176910771),
('boxoffice', 0.80589294692318436),
('television', 0.80580737502609401),
('FIlm', 0.80526562061786577),
('entertainment', 0.80518885985662325),
('horror', 0.78922592213993759),
('moviecritic', 0.78111979554699174),
('comedy', 0.72267163823374903),
('marvelstudios', 0.69814875205594795)]/r/nfl
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['nfl'])][('nfl', 1.0000000000000004),
('fantasyfootball', 0.89367361832507575),
('Tennesseetitans', 0.81992806264353901),
('KansasCityChiefs', 0.81785616443519937),
('minnesotavikings', 0.81305050937778889),
('Fantasy_Football', 0.80856182279988509),
('cowboys', 0.80494524364911568),
('LosAngelesRams', 0.79100488742119768),
('Patriots', 0.7840318338252712),
('buffalobills', 0.78022631220261829)]/r/dataisbeautiful
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['dataisbeautiful'])][('dataisbeautiful', 1.0000000000000002),
('InternetIsBeautiful', 0.68618942072102962),
('MachineLearning', 0.61182487912821226),
('javascript', 0.60323173803427721),
('Python', 0.60041269643377471),
('reactjs', 0.58750011122905088),
('programming', 0.58183771746746316),
('webdev', 0.56555730100160906),
('motivation', 0.55634548146043017),
('java', 0.55060891313209037)]/r/india
[(subreddits[r], s) for r, s in model.similar_items(subreddits_ids['india'])][('india', 0.99999999999999989),
('indianews', 0.88899975384886409),
('IndiaSpeaks', 0.8833569213859862),
('bakchodi', 0.86393956351005186),
('pakistan', 0.82199852188563871),
('Cricket', 0.8083716806631227),
('bollywood', 0.78534592933755132),
('indianpeoplefacebook', 0.688104745142472),
('Kerala', 0.68013967096682715),Recommendations
implicit library also provides model.recommend() to generate user-specific recommendation using list of items he likes. With reddit API, we can get the subreddits of interest for a reddit user, by looking at recent posts and comments data. Using the list of subreddits as user-profile, we can get new recommendations from the model.
Connect to reddit API
def author_subreddits(author):
url = "https://api.reddit.com/user/{}/submitted".format(author)
# https://www.reddit.com/dev/api/oauth#GET_user_{username}_submitted
# http://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
payload = {'limit': '100', 'sort': 'new'} # Most-recent 100 reddit posts
resp = requests.get(url, auth=reddit_auth, params = payload, headers = {'User-agent': 'chrome'})
subreddits = [ r['data']['subreddit'] for r in resp.json()['data']['children'] ]
return list(set(subreddits))
def author_items(a_subreddits):
active_ids = [subreddits_ids[s] for s in a_subreddits if s in subreddits_ids]
data = [n_posts for _ in active_ids] # Assume 10 posts in active subreddits
rows = [0 for _ in active_ids]
shape = (1, model.item_factors.shape[0])
return coo_matrix((data, (rows, active_ids)), shape=shape).tocsr()With new functionality added to implicit library by Juarez Bochi, we can now see explanations also along with user-specific item-recommendations.
def recommend(author_items):
recs = model.recommend(userid=0, user_items=author_items, recalculate_user=True)
return [(subreddits[r], s) for r, s in recs]
def explain(author_items, subreddit):
_, recs, _ = model.explain(userid=0, user_items=author_items, itemid=subreddits_ids[subreddit])
return [(subreddits[r], s) for r, s in recs]Recommendations for /u/spez
Let’s compute the recommendations for popular redditors mentioned in this blog by Felip Hoffa:
spez = author_items(author_subreddits('spez') )
recommend(spez)[('worldnews', 0.41962765308588484),
('news', 0.40926298460008137),
('nottheonion', 0.39674370249576651),
('politics', 0.3955158977981878),
('india', 0.36095457299514017),
('TropicalWeather', 0.35793863630303491),
('dataisbeautiful', 0.34413671654730171),
('inthenews', 0.3419012198213619),
('conspiracy', 0.33370577980561406),
('learnpython', 0.32718576643666397)]To look at reason behind recommendation,
explain(spez, 'worldnews')[('atheism', 0.14474076316881168),
('todayilearned', 0.12226239255069876),
('sports', 0.097744621282540883),
('The_Donald', 0.053550806420940601),
('programming', 0.019931820201193797),
('cscareerquestions', -0.018602750538300905)]Recommendations for /u/wil
# Wil Wheaton
wil = author_items(author_subreddits('wil') )
recommend(wil)[('todayilearned', 0.9519672716815093),
('mildlyinteresting', 0.91912160652252661),
('mildlyinfuriating', 0.81833013521266285),
('OldSchoolCool', 0.81222383453994595),
('gifs', 0.80772905399999551),
('WTF', 0.76609066839306661),
('oddlysatisfying', 0.75641449504735825),
('movies', 0.71394855058414752),
('Jokes', 0.70337572635830581),
('videos', 0.69795440758722682)]explain(wil, 'todayilearned')[('nottheonion', 0.095599276662095195),
('pics', 0.08130569672080562),
('creepy', 0.081217285500511716),
('photoshopbattles', 0.070843088126791756),
('funny', 0.065690510265598315),
('interestingasfuck', 0.05689208840228871),
('politics', 0.056387815873278353),
('Music', 0.055991864671039622),
('ProgrammerHumor', 0.047813558687162673),
('TheSimpsons', 0.045338399248090744)]Recommendations for a custom-list of subreddits
Let’s build a custom-list of subreddits, and check the recommendations for the custom-list.
n_posts = 10.
custom = author_items(['MachineLearning', 'science', 'space'])
recommend(custom)[('Futurology', 0.35250874397937865),
('technology', 0.33461688885765595),
('psychology', 0.33013781912189211),
('EverythingScience', 0.31051852362730364),
('news', 0.30641943808422778),
('Astronomy', 0.30501076666920923),
('energy', 0.28615324716372809),
('programming', 0.27123619696790718),
('worldnews', 0.2636338747438754),
('astrology', 0.26051125864920122)]explain(custom, 'energy')[('science', 0.12675927609142465),
('space', 0.097574084741807524),
('MachineLearning', 0.061819886330495885)]
